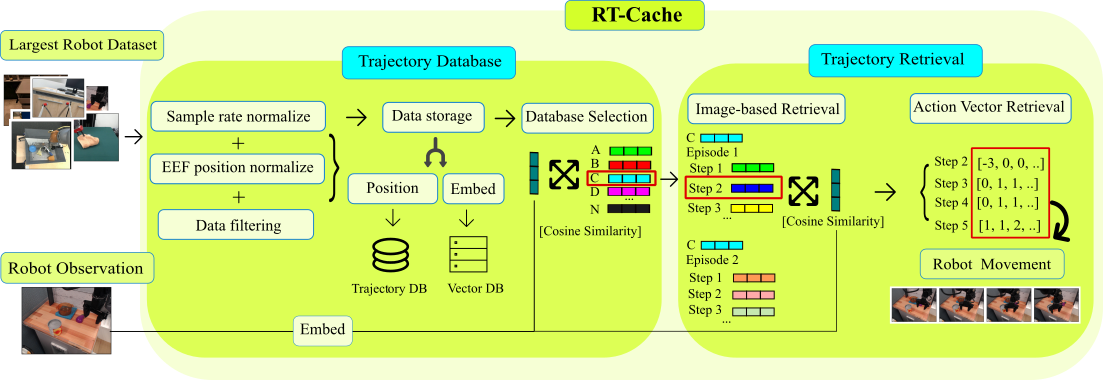
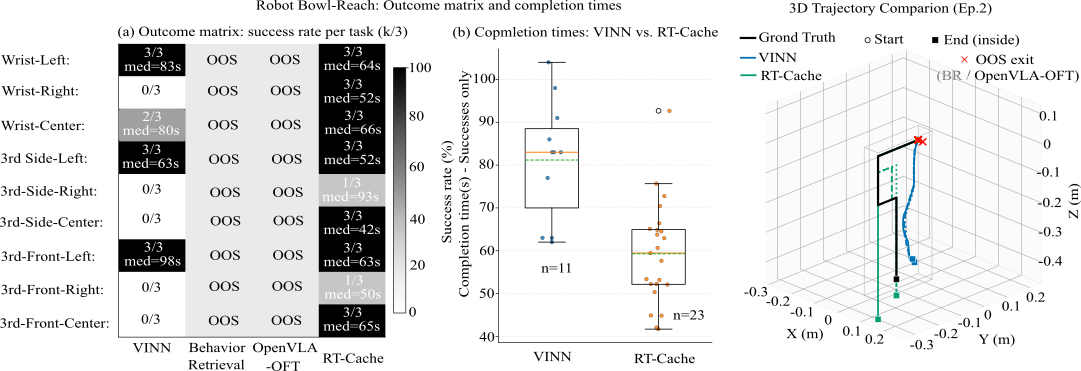
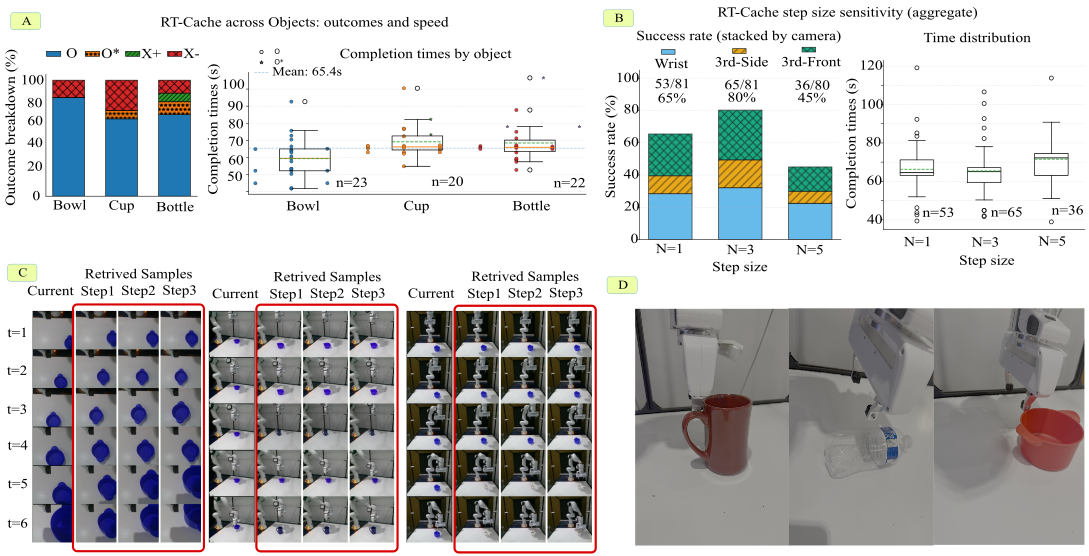
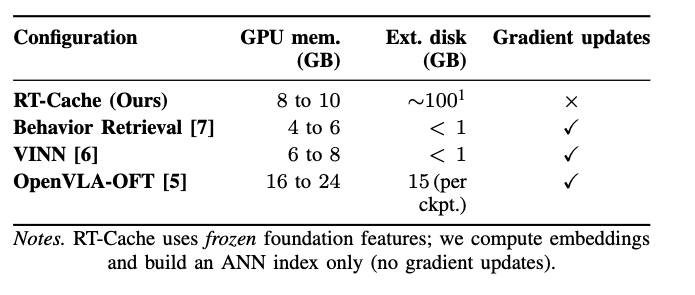
RT-Cache Overview
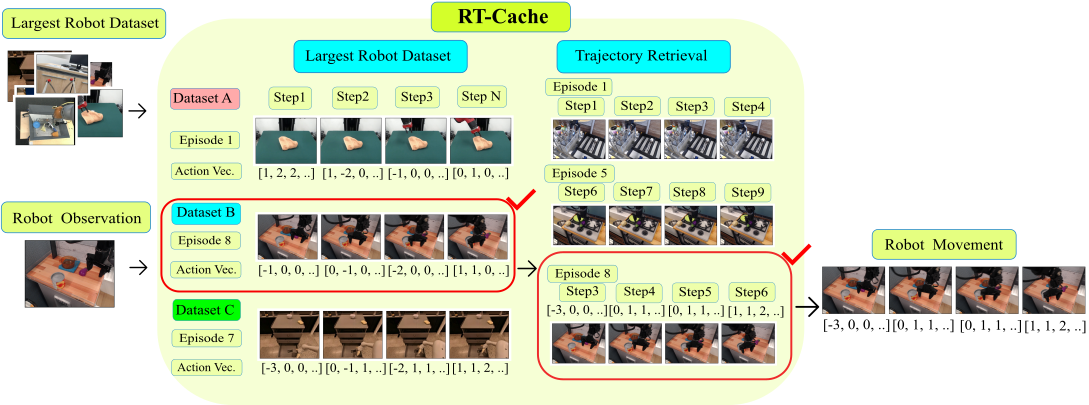
We turn prior robot experience into an append-only memory of image–action snippets. At deployment, the current camera frame is embedded, matched to similar snippets, and the best short segment is replayed for N steps; then we re-query and repeat. This training-free "retrieval-as-control" loop gives real-time, few-shot adaptation by simply appending new episodes.